0x00 背景
最近需要基本书的电子版,但是找来的PDF扫描版有些参差不齐,于是想起了之前在B乎上看到的一个PDF扫描加整理一条龙服务的回答,又回去翻看学习。
想把自己的书籍扫描成PDF,什么样的扫描仪比较合适? - 白垩纪的回答
得到的PDF长这个样子。
- 四周有黑边
- 纸张有些歪


0x01 提取图片
这里用到的是PDF补丁丁这个软件。
先对PDF的图片进行提取
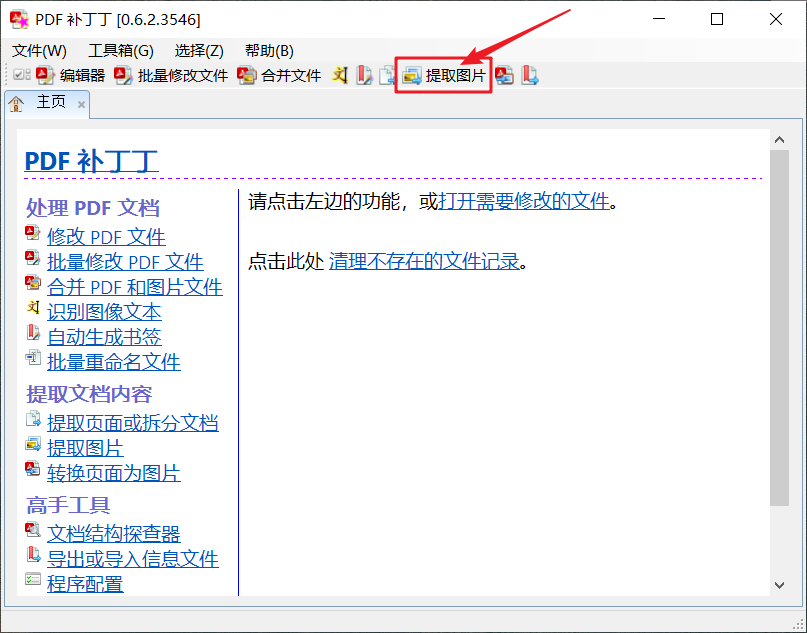
按照图示,操作,为图片建一个out文件夹,其余默认即可,保存所有的图片,便于后续处理。
提取完成

0x02 切边处理
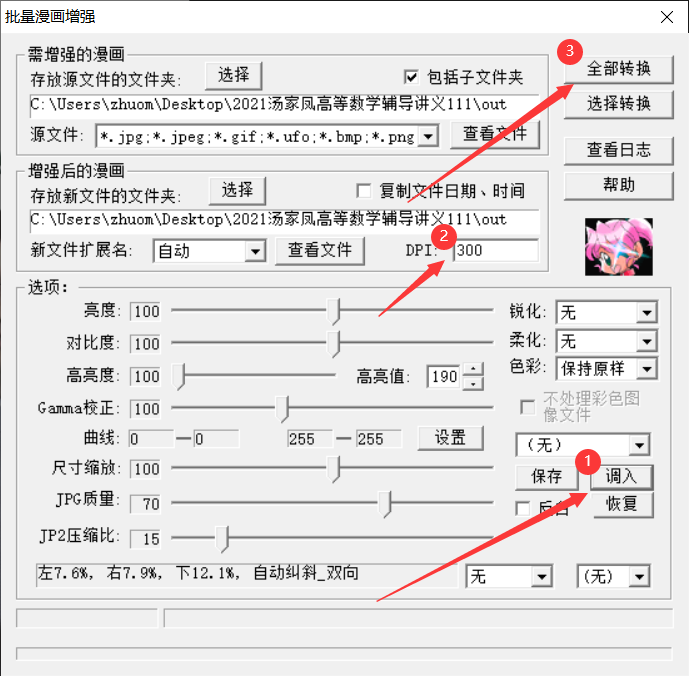
切边处理,使用ComicEnhancerPro这个软件。
任意打开一张图片,处理后,保存参数,便于批量处理。
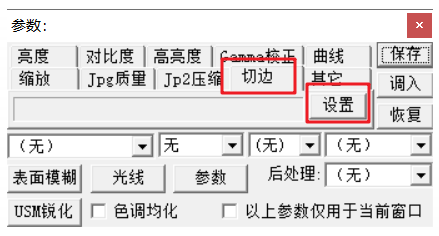
调整参数,自动纠斜、页面大小设置内容框大小(选择其他的可能会有空白的部分)、划线部分可以针对情况自己选、DPI改为600,确定。

切边后效果

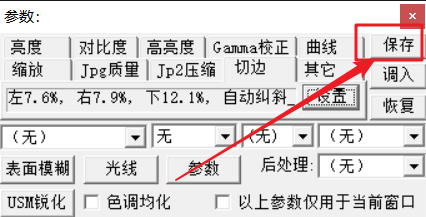
保存参数
批量处理
0x03 添加书签目录
这里我们使用两个软件一起操作。
FreePic2Pdf、PdgCntEditor,这两个软件一定要放到同一个目录下。
我们使用FreePic2PDF这个软件增加目录功能,使用PdfCntEditor的编辑目录功能。
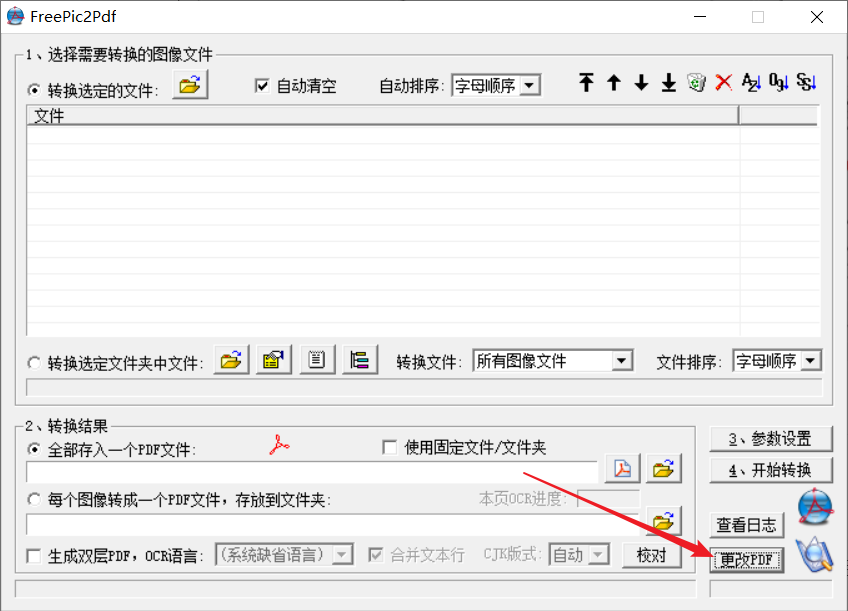
按照如下步骤操作,下面对步骤做一下解释。
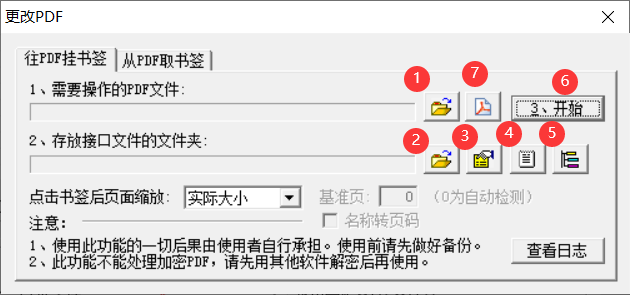
浏览PDF文件
选择存放
接口配置的文件夹,这里随便选择一个就可以编辑
接口配置按照如下配置编辑,
BasePage表示正文第一页,根据内容自行调整。[Images]
[Font]
Language=GBK
FontSize=7
Margin=0.5
[Bkmk]
File=FreePic2Pdf_bkmk.txt
AddAsText=0
ShowBkmk=1
ShowAll=1
BasePage=10
[Main]
ContentsPage=
TextPage=编辑目录,这里就仁者见仁智者见智了,推荐使用OCR文字识别,这里提供一种方法,把目录截图,然后使用百度翻译自带的OCR识别功能,选择上传文档,然后复制文字,在记事本里边做调整。

这里的格式大致为,
\t代表制表符,也就是Tab键,后边的1,2,3代表页码一级标题\t1
\t二级标题\t2
\t\t三级标题\t3二级三级目录可以使用软件里自带的工具栏调整缩进,以及其他部分。

Trick:
- 如果要给目录的位置再加一个书签,可以设置页码为负值。
保存。
预览目录树,看是否符合自己的要求。
操作之前把原来的PDF关闭,开始操作,等待操作完成。
重新打开是否符合要求,不符合再微调。
0x04 完成
0x05 补充
其他PDF优化的操作详见知乎页面
所需文件下载链接:
已完成: